

こんにちは!今回は、いろいろと話題になっているPDF高画質化ツール「DN_SuperBook_PDF_Converter」の使い方を解説します。 これを使うと、裏写りやノイズだらけの自炊PDFが、まるで電子書籍のようにクッキリ綺麗になります。さらにAI OCR機能までついているとのことです。
ただ、現時点では「ソフトそのもの」が配布されておらず、自分でビルドする必要があります。
READMEを見ればビルド方法が書いてあるのですが、いくつかつまずきポイントがあったため、備忘録を残します。
※特にPythonのバージョンは、READMEに書いてあるバージョン推奨です。
動作条件の詳細などはREADMEを見てください。結構スペックを要求されます。
1. 必要なものを準備しよう
まず、このソフトを動かすための「土台」となるソフトをインストールします。
① Visual Studio 2026 (または2022) のインストール
このツールは C# という言語で作られているため、MicrosoftのVisual Studio Community(無料版)が必要です。
- Microsoftの公式サイトから「Visual Studio Community」をダウンロードしてインストールします。
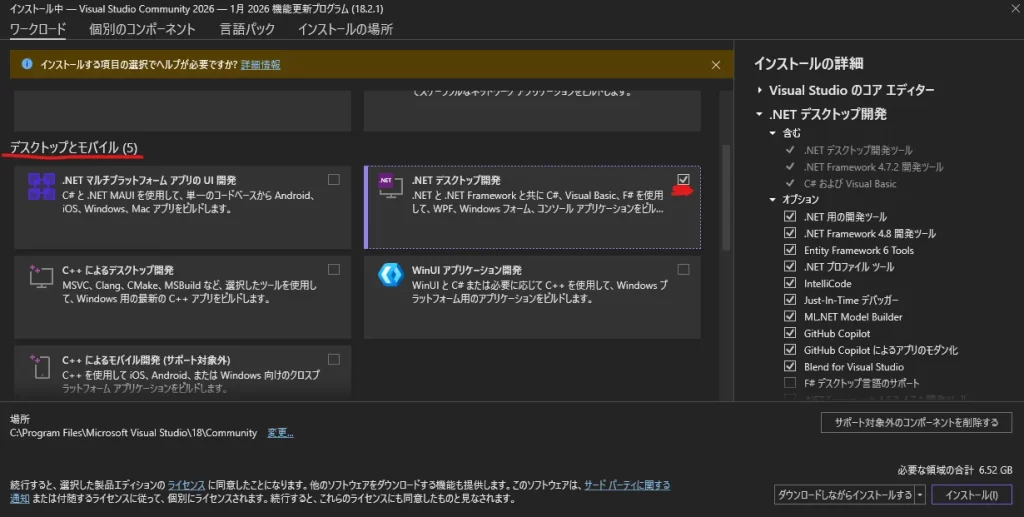
- 「ワークロード」タブで「.NET デスクトップ開発」にチェックを入れます(ここは同じ)。
- そのまま、画面の上部にある「個別のコンポーネント」というタブをクリックします。
- 検索バー(またはリスト)から、以下の項目を探してチェックを入れてください。
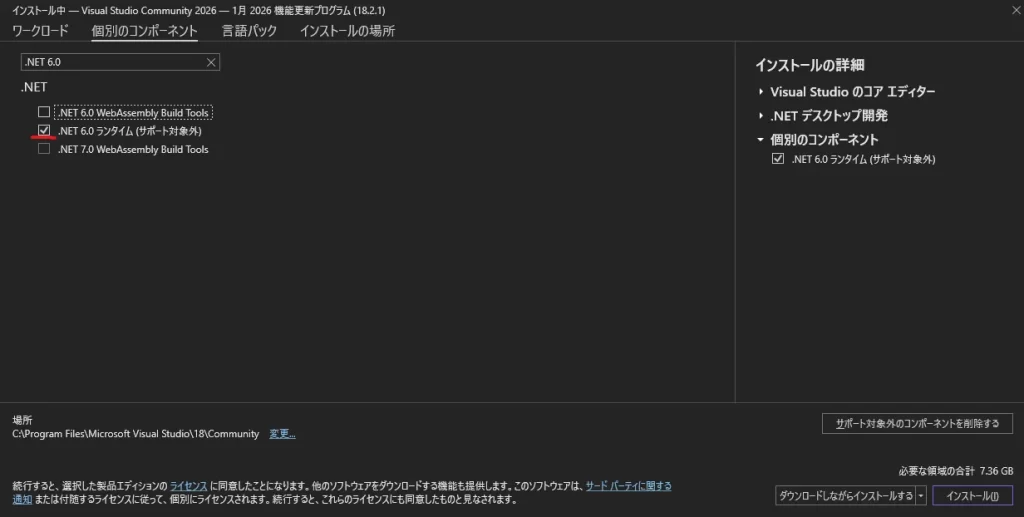
.NET 6.0 ランタイム (サポート対象外)- (もしあれば)
.NET SDK関連で6.0と書かれているもの(ブログ作成時点ではチェックをいれていません)
- ※ リストの中に「.NET 6.0」が見当たらない場合や、すでにチェックが入っている場合は、右側の「インストールの詳細」パネルの中に「.NET 6.0 ランタイム」が含まれているか確認できればOKです。
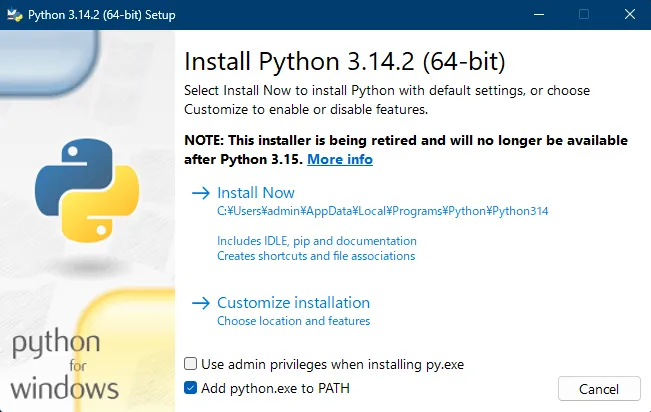
② Python(3.11推奨)のインストール
AI OCR機能(YomiTokuエンジン)を使うために必要です。
- Python公式サイトからインストーラーをダウンロードしてインストールします。
(例の画像は3.14.2ですが、最新すぎるとAIのライブラリ側が対応していないことが多いため、README記載のバージョンを入れることをお勧めします。) - インストールの最初の画面で、必ず「Add Python to PATH(環境変数に追加)」にチェックを入れてください。
③ 必要なAIライブラリを入れる
コマンドプロンプトを開き、以下のコマンドを入力してEnterキーを押します。これでAI OCRのエンジンが入ります。
pip install yomitoku
2. ソフトの「設計図」をダウンロードする
インストーラーがないので、GitHubからソースコード(設計図)をダウンロードします。
- GitHubのページ(https://github.com/dnobori/DN_SuperBook_PDF_Converter/)にアクセス。
- 緑色の**「Code」ボタンをクリックし、「Download ZIP」**を選択。
- ダウンロードしたZIPファイルを、好きな場所(デスクトップなど)に「すべて展開(解凍)」します。
3.AIエンジン(external_tools)の準備
このソフトは、本体(SuperBookToolsApp.exe)だけでは動きません。 裏方として働く「外部ツール(external_tools)」を、所定の場所に配置する必要があります。
READMEの「3.2」に書かれている内容は、大きく分けて2つの作業が必要です。
作業A:必須ツールのダウンロードと配置
README(3.2節)に、記載されてバージョンの各ソフトをダウンロードして配置します。
1. exiftool
- 入手先: ExifTool公式サイト
- 何をする?: 「Windows Executable」をダウンロードして解凍します。
- 注意点: 出てきた
exiftool(-k).exeというファイルの名前をexiftool.exeに書き換えて、フォルダに置いてください。
2. ImageMagick
- 入手先: ImageMagick公式サイト
- 何をする?: 「Windows Binary」の中にある 「Portable Win64 (zip)」 をダウンロードして解凍します。
- 配置: 解凍した中身をそのまま
ImageMagick-portable...フォルダの中に置きます。
3. ghostscript
- 入手先: ghostscript公式サイト
- 何をする?: ダウンロード&インストール
- 配置: C:\Program Files\gs\gs10.05.1\bin\の中にある`gsdll64.dll`, `gsdll64.lib`, `gswin64.exe`, `gswin64c.exe` という 4 個のバイナリファイルをそのまま
ImageMagick-portable...フォルダの中に置きます。
4. pdfcpu
- 入手先: GitHub – pdfcpu
- 何をする?: 最新の
pdfcpu_..._Windows_x86_64.zipをダウンロードして解凍し、pdfcpu.exeが入ったフォルダを置きます。
5. QPDF
- 入手先: GitHub – qpdf
- 何をする?:
qpdf-..-msvc64.zip(または mingw64) をダウンロードして解凍。binフォルダの中にqpdf.exeがある状態にします。
6. RealEsrgan (画質を良くするAI)
- 各種コマンドを実行し、環境を整えます。
1.RealEsrgan_Repoというフォルダを作成します。
ダウンロードした下記フォルダで、コマンドプロンプトを開きます。
…\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\
mkdir RealEsrgan_Repo\2.作成したディレクトリへ移動
cd RealEsrgan_Repo3.Pythonの仮想環境を作成
<pythonをインストールしたディレクトリ>Python311\python.exe -m venv venv※デフォルトでは、%LOCALAPPDATA%\Programs\Python\Python311\python.exeのはず
4.仮想環境の有効化
venv\Scripts\activate5.pipの最新化
python -m pip install --upgrade pip6.AI計算用のライブラリを仮想環境にインストール
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu1287.Real-ESRGANの本体をダウンロード
ダウンロード先のディレクトリをあらかじめ作成しておく。
mkdir Real-ESRGANREADMEに記載されているバージョンの本体をダウンロードして、中身を先ほど作成したディレクトリに入れる
例:checkout a4abfb2979a7bbff3f69f58f58ae324608821e27
ならば、https://github.com/xinntao/Real-ESRGAN/archive/a4abfb2979a7bbff3f69f58f58ae324608821e27.zip
でDLできる。
下記のURLからファイルをDLして、上記でDLしたweightsフォルダの中に格納。
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth
以下を 実行します。
pip install -r Real-ESRGAN\requirements.txtダウンロードした下記のファイルの一部を書き換えを行います。(任意のテキストエディタでOK)\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\venv\Lib\site-packages\basicsr\data\degradations.py
旧:
```
from torchvision.transforms.functional_tensor import rgb_to_grayscale
```
新:
```
from torchvision.transforms.functional import rgb_to_grayscale
```最後に
\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\Real-ESRGAN\realesrgan\version.py` というファイル名の、内容が空のファイルを作成します。
7. yomitoku (最強の日本語AI OCR)
1.yomitoku用のpython仮想環境を作成します。
ダウンロードした下記フォルダで、コマンドプロンプトを開いて下記コマンドを実行
…\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\yomitoku\
<pythonをインストールしたディレクトリ>Python311\python.exe -m venv venv※デフォルトでは、%LOCALAPPDATA%\Programs\Python\Python311\python.exeのはず
2.仮想環境の有効化
venv\Scripts\activate3.pipの最新化
python -m pip install --upgrade pip4.AI計算用のライブラリを仮想環境にインストール
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu1285.yomitokuを仮想環境にインストール
pip install "yomitoku==0.10.3"※バージョンはREADMEに従ってください。
8. TesseractOCR_Data (予備のOCRデータ)
- 入手先: GitHub – tessdata_best
- 何をする?:
jpn.traineddata(日本語用)eng.traineddata(英語用)jpn_vert.traineddata(縦書き用・あれば)- これらをダウンロードして、このフォルダの中に放り込みます。
配置後のイメージ
最終的に、フォルダの中身がこうなっていれば準備完了です!
...\image_tools\
├─ exiftool\ (中に exiftool.exe)
├─ ImageMagick-portable...\ (中に magick.exe など)+ghostscriptのファイル群
├─ pdfcpu\ (中に pdfcpu.exe)
├─ QPDF\ (中に bin\qpdf.exe)
├─ RealEsrgan\RealEsrgan_Repo(中に venv や Real-ESRGAN のファイル群)
├─ yomitoku\ (中に venv のファイル群)
└─ TesseractOCR_Data\ (中に .traineddata ファイル)4. ソフトを「ビルド(組み立て)」する
外部ツールのインストールお疲れさまでした。ここまでくればビルドするだけです。
- 展開したフォルダの中に、
DN_SuperBook_PDF_Converter_VS2026.slnというファイルがあります。これをダブルクリックします。- → Visual Studio が立ち上がります。
- 画面上のメニューにある「ビルド」から**「ソリューションのビルド」**をクリックします(または
Ctrl + Shift + B)。 - 画面下のほうに文字が流れます。最後に**「ビルド: 1 正常終了」**と出れば成功です!
- ※もしエラーが出る場合、.NETのバージョンなどが足りない可能性があります。Visual Studioのインストーラーで最新のSDKを入れてください。
5. いざ、実行!
ビルドが成功すると、フォルダの奥深くに実行ファイル(.exe)が出来上がっています。
ファイルの場所(例): フォルダ名\SuperBookToolsApp\bin\Debug\net6.0\ この中に SuperBookToolsApp.exe というファイルがあるはずです。
使い方は「コマンド」で
このソフトには画面(GUI)がありません。「コマンドプロンプト」や「PowerShell」を使って指示を出します。
- 変換したいPDFが入ったフォルダ(入力用)と、空のフォルダ(出力用)を用意します。
- コマンドプロンプトを開き、以下の形式で命令します。
DOS
SuperBookToolsApp.exe ConvertPdf /src:"入力フォルダのパス" /dst:"出力フォルダのパス" /ocr:yes
- ConvertPdf: PDFを変換モードにする合言葉。
- /src: 元のPDFが入っているフォルダ。
- /dst: 変換後のPDFを保存するフォルダ。
- /ocr:yes: AIによる文字認識を行うオプション(めちゃくちゃ綺麗になりますが、時間がかかります)。
実行すると、ズラズラと処理状況が表示され、出力フォルダに驚くほど綺麗なPDFが出来上がります!
まとめ:一般公開版を待つのもアリ?
正直なところ、この手順はパソコンに慣れていないとかなり大変です。 開発者の登さんは非常にユーザー思いの方なので、しばらく待てば、ダブルクリックだけでインストールできる「リリース版」が公開される可能性が高いです。
「今すぐ試したい!」という方は上記の手順でチャレンジしてみてください。成功したときの画質の感動はすごいですよ!

コメント